Introduction
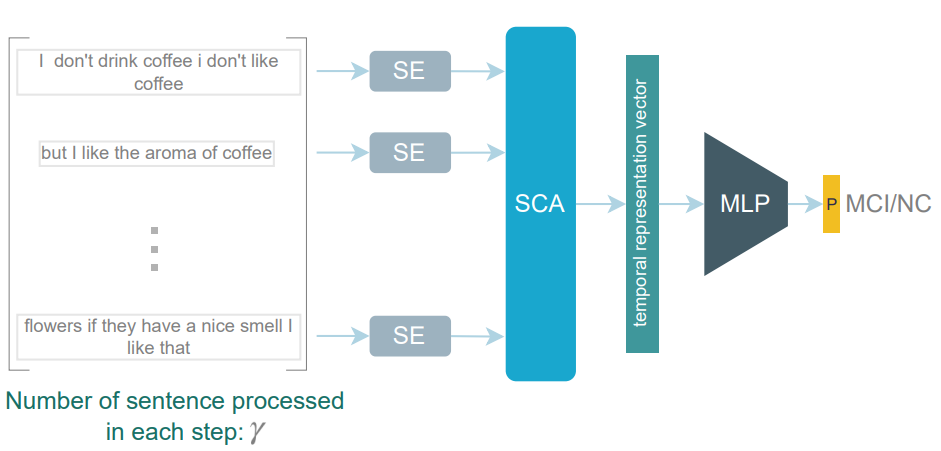
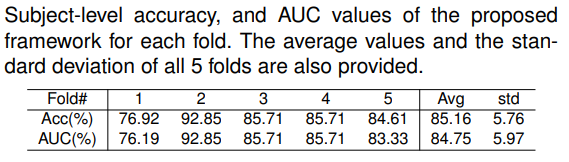
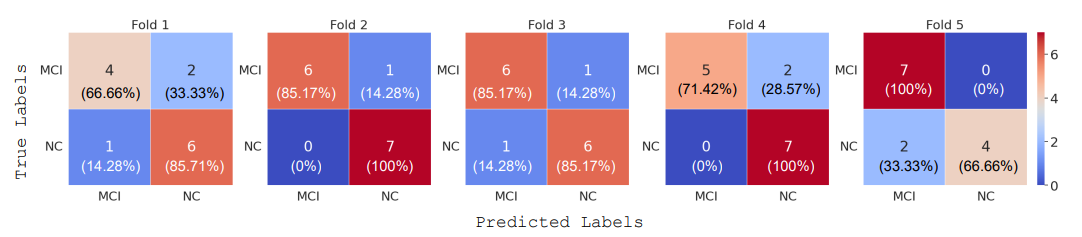
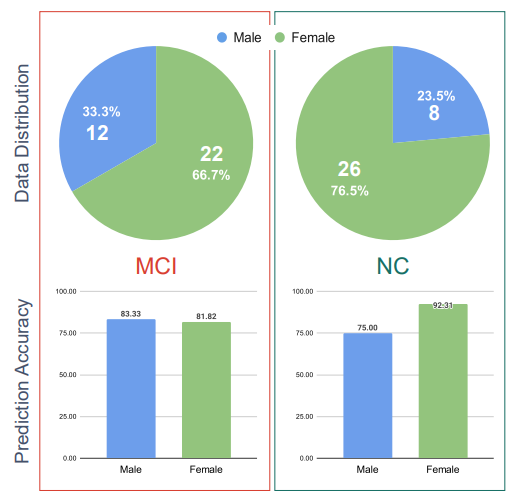
I proposed a deep learning approach employing Natural Language Processing (NLP) techniques to differentiate between Mild Cognitive Impairment (MCI) and Normal Cognitive (NC) conditions in older adults. In this study, I presented a framework that analyzed transcripts obtained from video interviews conducted as part of the I-CONECT study project, a randomized controlled trial aimed at improving cognitive functions through video chats. My NLP framework comprised two Transformer-based modules: Sentence Embedding (SE) and Sentence Cross Attention (SCA). Initially, I utilized the SE module to capture contextual relationships among words within each sentence, while the SCA module extracted temporal features from sequences of sentences. These features were then employed by a Multi-Layer Perceptron (MLP) for subject classification into MCI or NC categories. To ensure the robustness of my model, I introduced a novel loss function called InfoLoss, which considered entropy reduction observed in each sentence sequence to enhance classification accuracy. The comprehensive evaluation of my model using the I-CONECT dataset demonstrated that my framework achieved an average area under the curve of 84.75% in distinguishing between MCI and NC.